
En muchas ocasiones necesito dibujar un diagrama que ilustre alguna explicación. Estos diagramas suelen ser complejos y, en muchos casos, repetitivos. Por ejemplo, una tabla de páginas con sus correspondientes marcos de página físicos y flechas que los conecten. O una red compleja. En muchos casos hay un programa específico que lo puede hacer.
Yo suelo usar DIA o una extensión de Google Drive llamada Draw.io para los diagramas simples o que necesitan ser vistosos.
Pero, en ocasiones, echo de menos una manera de hacerlo automático. Para ello se puede usar un programa muy veterano llamado Graphviz. Este programa lleva más de 26 años funcionando y dibuja los diagramas interpretando el lenguage DOT. Es muy probable que el estilo nos resulte familiar, como el de los diagramas de los libros teóricos de la universidad.
Gracias a que DOT es un lenguaje relativamente fácil de generar con scripts, puedo crear diagramas complejos a partir de otros datos o inventados.
Por ejemplo, este código permite mostrar un diagrama de la red de contenedores LXD:
#!/bin/bash
echo 'digraph {
graph [pad="0.5", nodesep="0.5", ranksep="2", splines=ortho,];
node [shape=none]
rankdir=LR;'
bridges=($(brctl show | tail -n +2 |cut -f1 | tr "\n" " "))
for i in ${bridges[@]}
do
echo "$i [label=\"$i\" shape=box];"
done
containers=($(lxc list | egrep '(STOPPED|RUNNING)' | cut -d" " -f2 | tr "\n" " "))
xarxes="$(lxc list --format json | jq -r '.[] | {container: .name, dev: .expanded_devices[]} | [.container,.dev.name,.dev.parent,.dev.type] | @csv' | grep '"nic"$')"
relations=""
for i in ${containers[@]}
do
pc="$i [label=<<table border=\"0\" cellborder=\"1\" cellspacing=\"0\"><tr><td bgcolor=\"#CCCCCC\" >$i</td></tr>"
while read dev
do
nom=$(echo $dev | cut -d "," -f2 | tr -d '"')
switch=$(echo $dev | cut -d"," -f3 | tr -d '"')
pc=$pc"<tr><td port=\"$nom\">$nom</td></tr>"
#La IP
ip=$(lxc info $i | tr "\t" " " | grep "$nom: inet " | tr -s " " | cut -d" " -f4)
relations=$relations"$switch -> $i:$nom [dir=none headlabel=\"$ip\"] \n"
done <<< "$(echo "$xarxes" | grep "$i")"
pc=$pc"</table>>];"
echo $pc
done
echo -e "$relations"
echo '}'
Esto genera un fichero DOT como este:
digraph {
graph [pad="0.5", nodesep="0.5", ranksep="2", splines=ortho,];
node [shape=none]
rankdir=LR;
lxdbr0 [label="lxdbr0" shape=box];
switch1 [label="switch1" shape=box];
switch2 [label="switch2" shape=box];
dns1 [label=<<table border="0" cellborder="1" cellspacing="0"><tr><td bgcolor="#CCCCCC" >dns1</td></tr><tr><td port="eth1">eth1</td></tr></table>>];
dns2 [label=<<table border="0" cellborder="1" cellspacing="0"><tr><td bgcolor="#CCCCCC" >dns2</td></tr><tr><td port="eth1">eth1</td></tr></table>>];
firewall [label=<<table border="0" cellborder="1" cellspacing="0"><tr><td bgcolor="#CCCCCC" >firewall</td></tr><tr><td port="eth0">eth0</td></tr><tr><td port="eth1">eth1</td></tr></table>>];
pc1 [label=<<table border="0" cellborder="1" cellspacing="0"><tr><td bgcolor="#CCCCCC" >pc1</td></tr><tr><td port="eth1">eth1</td></tr></table>>];
pc2 [label=<<table border="0" cellborder="1" cellspacing="0"><tr><td bgcolor="#CCCCCC" >pc2</td></tr><tr><td port="eth1">eth1</td></tr></table>>];
switch1 -> dns1:eth1 [dir=none headlabel="10.20.30.100"]
switch1 -> dns2:eth1 [dir=none headlabel="10.20.30.200"]
lxdbr0 -> firewall:eth0 [dir=none headlabel="10.150.173.32"]
switch1 -> firewall:eth1 [dir=none headlabel="10.20.30.254"]
switch1 -> pc1:eth1 [dir=none headlabel=""]
switch1 -> pc2:eth1 [dir=none headlabel="10.20.30.2"]
}
El resultado sería algo así:
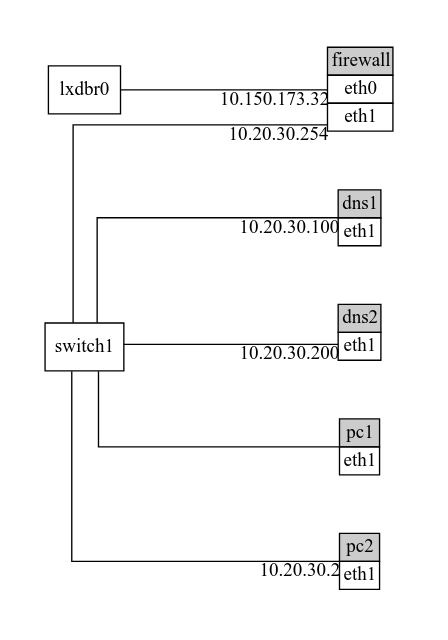
Para hacer el gráfico hago uso de jq i de la extension html-like de graphviz.


